
RESEARCH
研究内容
This Lab, born in April, 2020, is a research unit for computer vision and machine learning. We conduct various research topics to replace human visual sensing with machine. Target applications include, but not limited to, sensing algorithms for autonomous driving and advanced driver assistance systems, anomaly detection, image processing, and multimedia signal processing. We also work on more basic topics that aid broader applications. Introduction slides of Sato Lab: [Sato Lab Intro] [Research Theme]
From April, 2025, Dr. Kenta Hoshino joins our lab as a faculty member. We will start a new theme about Data-Driven Control.
Memory Models
記憶モデル
The modern Hopfield network is known as a model for memory formation and recall in the brain. By combining linear associations with simple activation functions, it enables the retrieval of discrete signals. However, challenges remain regarding its behavior on out-of-distribution data. This work establishes a principled solution to this issue. [AAAI 2025 paper, poster] [AISTATS 2023 paper, poster]
Co-Adaptation Breaking for Generic Feature Extraction
汎用特徴抽出のための共適合抑制
Generally speaking, human is amazingly good at recognizing the surroundings, often with full of objects, people, structure, etc. Say, if one wants to replace human by machine in driving, a number of recognition tasks such as pedestrian detection, vehicle detection, drivable area recognition roadway recognition, line marking detection, traffic sign recognition, traffic light recognition, etc. need to be processed in real time. The extraction of generic features from sensor input for various recognition tasks is regarded as one of core technologies for autonomous driving. Phenomena known as co-adaptation among neurons often bring situation where feature distribution is excessively complex so that very specific data can be handled. We develop new optimization methods that avoid such unwanted situations and generate well-generalized features. [ICML 2019 paper, slides] [EI 2021 paper, slides] [ICML 2022 paper, slides] [ACCV 2024 paper]
モビリティにおける省人化を実現するには、多種多様な外環境の認識問題を可解にする必要がある。例えば人が行う運転行動を機械で代替するには、歩行者認識・車両認識・走行路認識・白線認識・信号認識・標識認識を始めとした数多くの認識タスクの実時間処理が求められる。センサー入力から様々な認識タスクに汎用的な特徴量を抽出することは、これら複合的な外界認識器の中核的技術として重要な意味を持っている。しかし一方,深層学習において,ニューロン間の共適合と呼ばれる,特徴分布を過度に複雑化させてしまう事象が知られている.このような事象を抑制し,よりよく汎化された特徴を生成できる最適化手法を開発する.[ICML 2019 paper, slides] [EI 2021 paper, slides] [ICML 2022 paper, slides] [ACCV 2024 paper]
Model Compactification
モデルのコンパクト化
In safety-critical perception systems such as autonomous driving, real-time processing is a crucial requirement. In general, higher-accuracy models require longer inference times. Therefore, there is a growing need for model compression techniques that significantly accelerate inference while minimizing performance degradation. In particular, we focus on developing techniques for network quantization. [ACCV 2024 paper, poster] [ICASSP 2025 paper]
Target Propagation
目標値伝播法
Backpropagation has long been a central technique supporting artificial neural networks. However, it is known that its underlying principles differ from those of learning in the brain in several respects. In contrast, target propagation is a learning method that explicitly employs a backward signal propagation network, and is considered to have a certain degree of biological plausibility. Although current models trained with target propagation fall short of backpropagation in terms of performance, given the remarkable capabilities of the human brain, it is natural to see great potential in this approach. Our aim is to address the stability issues in learning with target propagation through a simple and effective method. [AAAI 2023 paper, poster] [AAAI 2024 paper]
誤差逆伝播法は長きに渡って人工ニューラルネットワークを支えてきた要の技術である。しかしながら、その原理は脳における学習とはいくつかの点において乖離があることが知られている。一方、目標値伝播法は信号の逆伝播ネットワークを陽に持つ学習法であり、生態学的に一定の妥当性を持つ学習法である。現状、モデル性能において、目標値伝播法は誤差逆伝播法に引けを取るものの、大脳がこれほど高度な機能を持つことを思うと、目標値伝播法に大きなポテンシャルを感じるのは自然なことと言える。我々は目標値伝播法の学習の安定性の問題をシンプルな方法で解決することを目指す。[AAAI 2023 paper, poster] [AAAI 2024 paper]
Image Syntheses
画像合成
In applications such as parking assistance, accurate recognition of the shapes of objects around the vehicle—as well as intuitive presentation to the driver—is essential. We develop a technology that captures three-dimensional shapes and synthesizes views from arbitrary perspectives. [ICIP 2024 paper, poster] [IBISML 2024 paper]
Retrieval Based on Semantic Distance
意味的距離に基づく検索
Here is a pen. You see it, and immediately understand there is a pen. You never thought of possibilities that it might be a pickup truck or Indian Rhino. Well, current state-of-the-art image classifiers do think such possibilities and return the most likely one. Human measures a sort of distance between what is seen and some instance that was seen before. The development of a technique for estimating the semantic distance between data samples not just contributes to industry, but pushes AI to next stage. It will enable estimation of data rareness and data classification under class indeterminacy. We study way of mapping into semantic space in a computationally efficient fashion. [ACM MMAsia 2022 paper, slides]
Inheritance of Generalization Capabilities between Machine Learning Models
機械学習モデル間の汎化能力の継承
Inference at the edge devices is required to achieve high generalization capability and real-time processing under limited power consumption. Large-scale deep neural network models consisting of many layers show high generalization capabilities, but the computational load is often too large to embed into an edge device. We study methods for model compactification, such as large-scale knowledge distillation. [ECCV 2022 paper, slides]
Analysis of Learning Processes in Deep Learning
深層学習における学習過程の解析
It is known that the performance of a deep neural network model is highly dependent on an initial set of values called hyperparameters. Selection of hyperparameters is done heuristically most of the time; the relation to the generalization ability is not fully elucidated yet. In recent years, attempts have been made to describe the learning process in deep learning by thermodynamic motion, which has led to a better understanding of the mechanism of generalization. We conduct research to better understand this mechanism by collecting and analyzing various statistics in the learning process by large-scale computation.
深層ニューラルネットワークモデルの性能は、複数のハイパーパラメタと呼ばれる初期設定値に大きく依存することが知られている。モデルの開発においては、それらのいくつかの組み合わせを用いて実際に学習・評価することで、より良いモデルを生成することが一般的である。近年、深層学習における学習過程を熱力学的な運動によって記述する試みが成され、これにより汎化能力を獲得するメカニズムの理解が進みつつある。学習過程における種々の統計量を大規模計算によって収集・解析することで、このメカニズムをより深く理解するための研究を行う。[IBIS 2019 poster]
Model Mixture
モデル混合
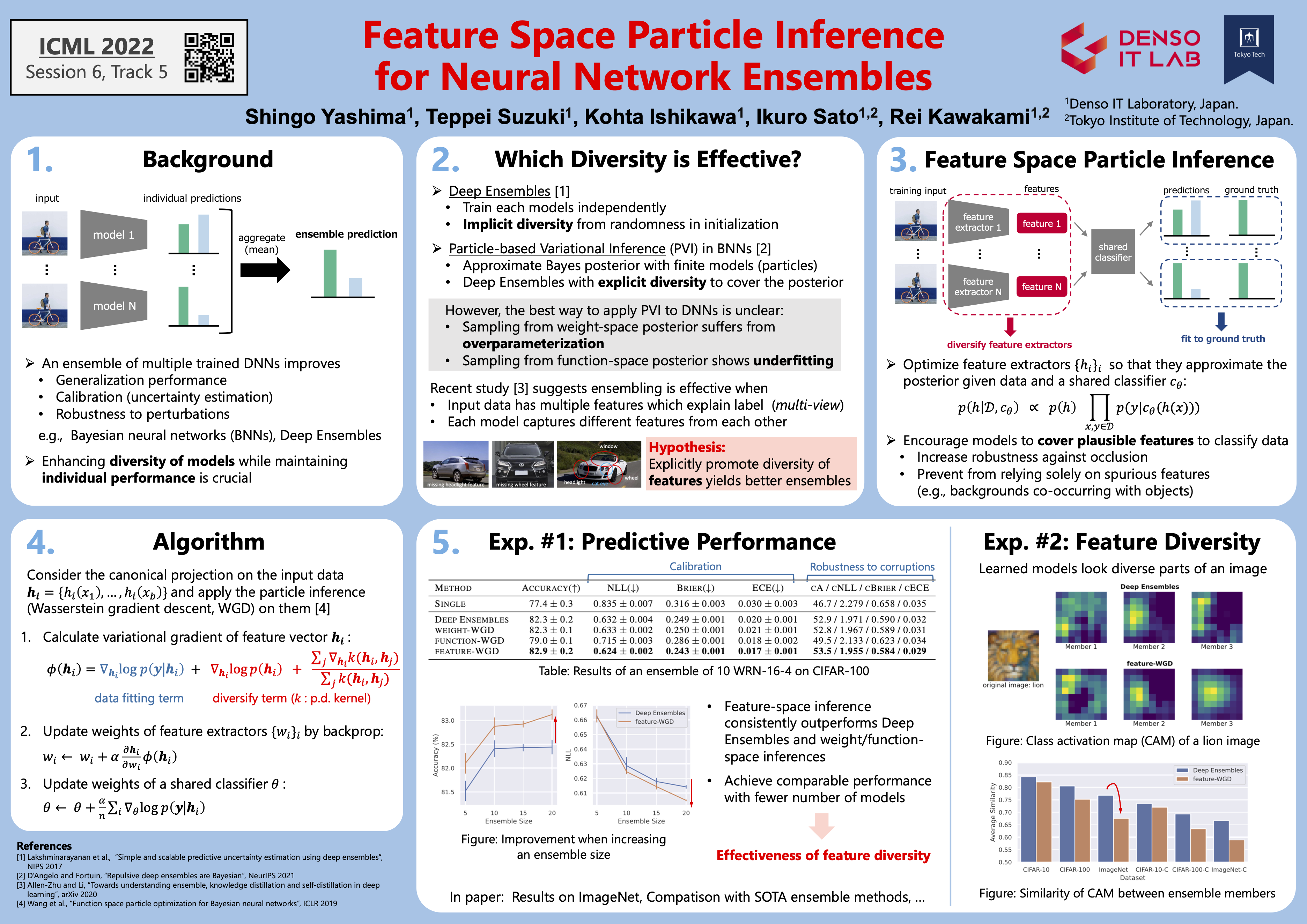
Studies of the learning process have shown that a certain inference bias is potentially present in a single deep neural network model. Model mixture is effective in correcting the bias and has been used in many situations, but the method remains in the heuristic phase. Research is focused on establishing a basic understanding and methodology of model mixture. [ICML 2022 paper, poster] [OJSP 2025 paper, slides, poster]
{kind=link}
Learning of Multiple Datasets
複数データセットの学習
It has been well demonstrated that a large model learned from a large dataset exhibits great performance, but the cost of building such a large dataset is way too huge today. If we can develop a system where learning of a set of many datasets can compete, the cost becomes much cheaper. We develop algorithms for learning multiple datasets. [NeurIPS 2022 WS paper, poster] [ICONIP 2024 paper, slides]
{kind=link}
Motion Sequence Modeling
運動の時系列モデリング
Generation of motion sequences such as human motion helps us understand how the world changes and control our states accordingly. There are several technical challenges such as long motion generation, physical consistency, object-subject interactions, etc. [ECCV 2022 paper] [IEEE Sensors 2023 paper] [WACV 2025 Workshop paper, slides]